Parsing Structured Documents with Custom Entity Extraction

Build your own custom entity extraction model with easy-to-use Machine Learning tools
There are lots of great tutorials on the web that explain how to classify chunks of text with Machine Learning. But what if, rather than just categorize text, you want to categorize individual words, like this:

This is called entity extraction (or named-entity recognition) and it comes in handy a lot. You could use this technique, for example, to pick out all of the people and places mentioned in news articles and use them as article tags (newsrooms sometimes do this).
Entity Extraction (EE) is also useful for parsing structured documents like forms, W4s, receipts, business cards, and restaurant menus (which is what we’ll be using it for today).
For Google I/O this year, I wanted to build an app that could take a photo of a restaurant menu and automatically parse it — extracting all of the foods, their prices, and more. (You can see me demo it on stage here.)
I wanted to be able to upload a picture of a menu like this:

And then use machine learning to magically extract entities from the menu, like the restaurant’s address, phone number, all of the food headings (“Salads,” “Mains”), all of the foods, their prices, and their descriptions (i.e. “on a pretzel bun”).
The idea was that if you’re a restaurant that wants to get listed on an app like Seamless or Grubhub, you could input your menu without having to manually type the whole thing out.
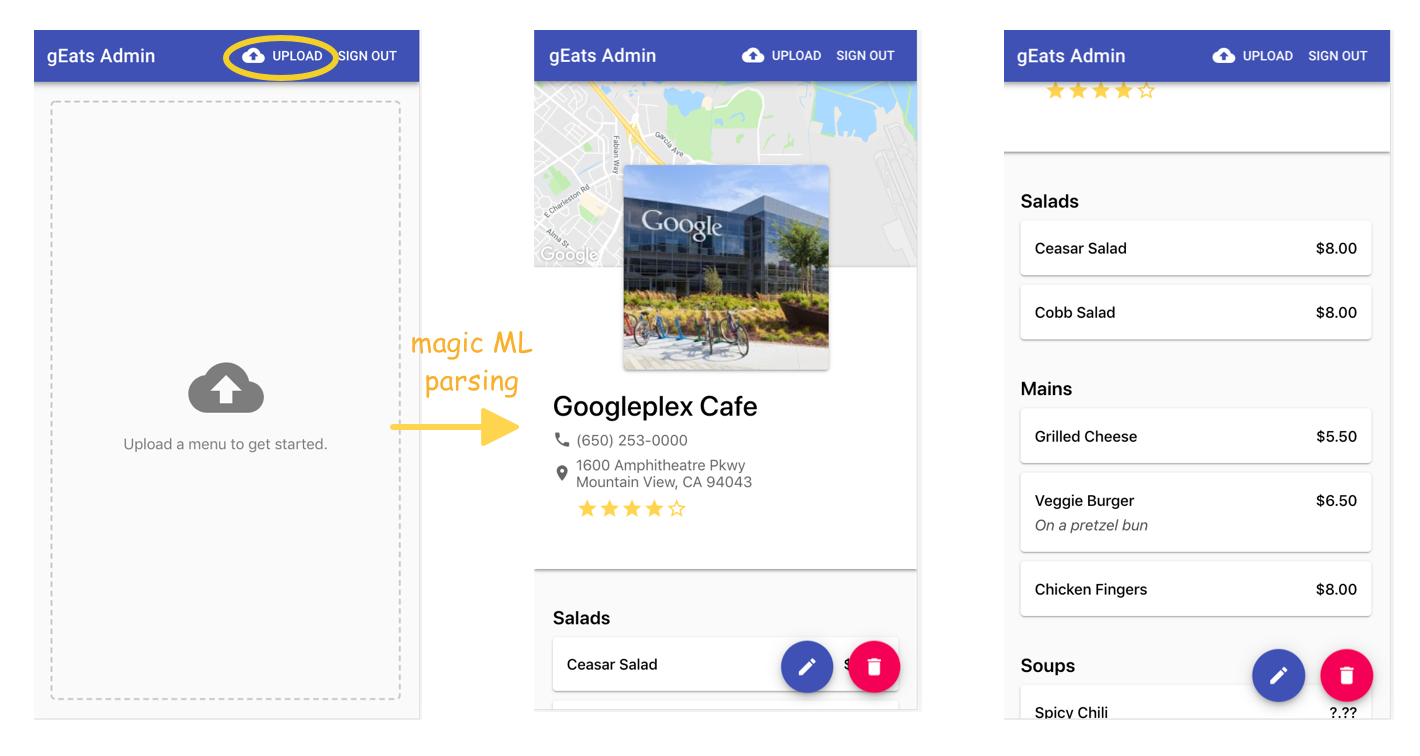
So how does it work?
First, I used the Google Cloud Vision API’s text detection feature to convert my picture of a menu into raw text.
Once I had my menu in text format, I used entity extraction to parse it. I did this with two techniques:
- I extracted the restaurant’s address, phone number, and all of the listed prices by using the Google Cloud Natural Language API.
- To identify food items, headings, and food descriptions, I had to build a custom machine learning model (more on that later).
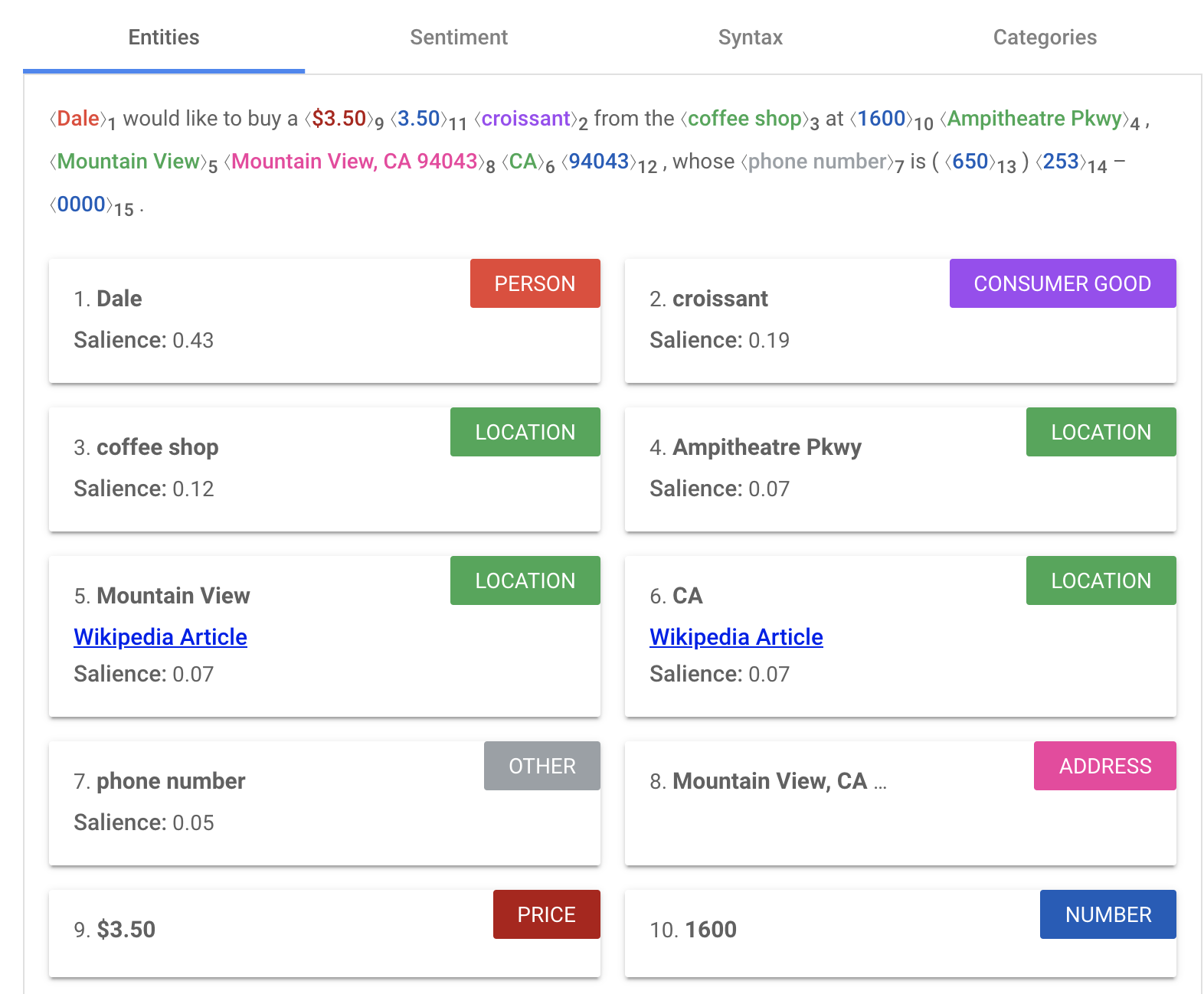
The Natural Language API is able to automatically detect common entities. For example, if I send it the string:
Dale would like to buy a $3.50 croissant from the coffee shop at 1600 Ampitheatre Pkwy, Mountain View, CA 94043, whose phone number is (650) 253–0000.
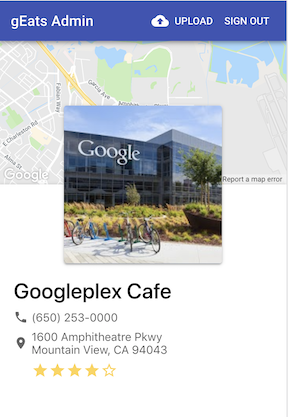
Next, I made my app a little sleeker by adding a restaurant photo, star ratings, and a map. None of this info was directly printed on the menu, but the restaurant’s phone number was. Using this phone number, I could query the Google Places API to pull photos, star ratings, etc.
Building a Custom Entity Extraction Model
Okay, but now for the hard (and most critical) bit: how do we extract all of the foods on the menu? And how do we tell the difference between what a food item is (“Veggie Burger”), what a food heading is (“Entrees”), and what a food description is (“on a pretzel bun”)?
These entities are totally domain-specific. In our case, we want to recognize that “entree” is a food heading. But if we were instead parsing newspapers, we might want to recognize the difference between headlines and article text. Or if we were analyzing resumes, we’d want to identify that “Sr. Software Engineer” is a job title, and “Python” is a programming language.
While the Natural Language API I mentioned before recognizes phone numbers and addresses and more, it’s not trained to recognize these domain-specific entities.
For that, we’ll have to build a custom entity extraction model. There are lots of ways of doing this, but I’ll show you the one I think is easiest (with minimal code), using Google AutoML Natural Language. We’ll use it to train a custom entity extraction model.
It works like this:
- Upload a labeled dataset of menus
- Train a model
- Use your model to identify custom entities via a REST API
Labeling Data
But where to find a dataset of labeled menus?
Conveniently, I found this nice dataset of scans of menus hosted (and labeled!) by the New York Public Library. Sweet!
To get started, I used the Vision API again to convert all of the menus in that dataset to text.
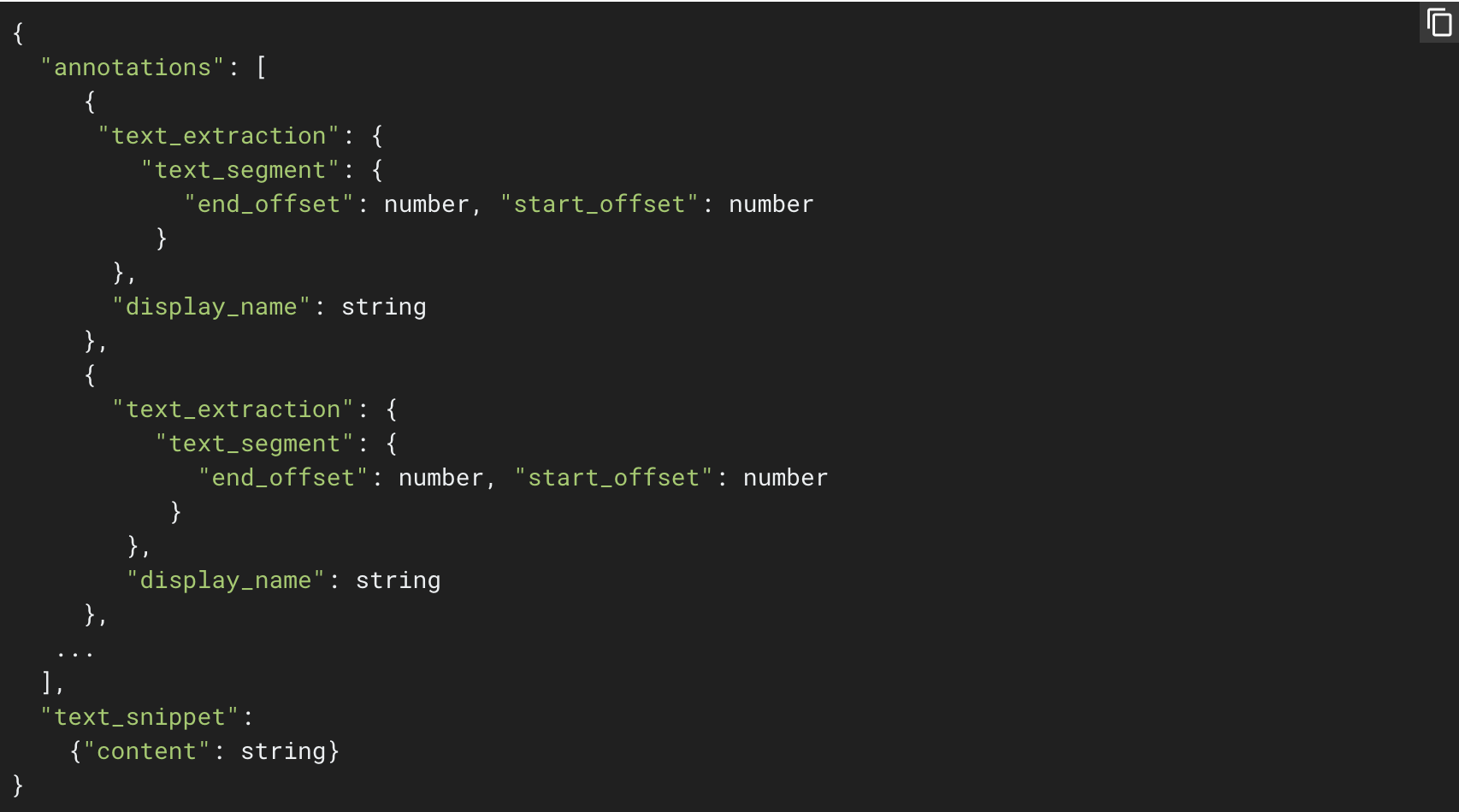
In order to train a custom entity extraction model, I had to transform my data and its labels into jsonl format (the format that AutoML expects). It looks like this:
I’m going to be honest and warn you that actually labeling these menus was a pain. I used some hackish Python script to pair the dataset’s labels with the OCR-extracted menu text, but they often didn’t line up. I had to go into the AutoML UI and hand-label a bunch of these menus, like this:
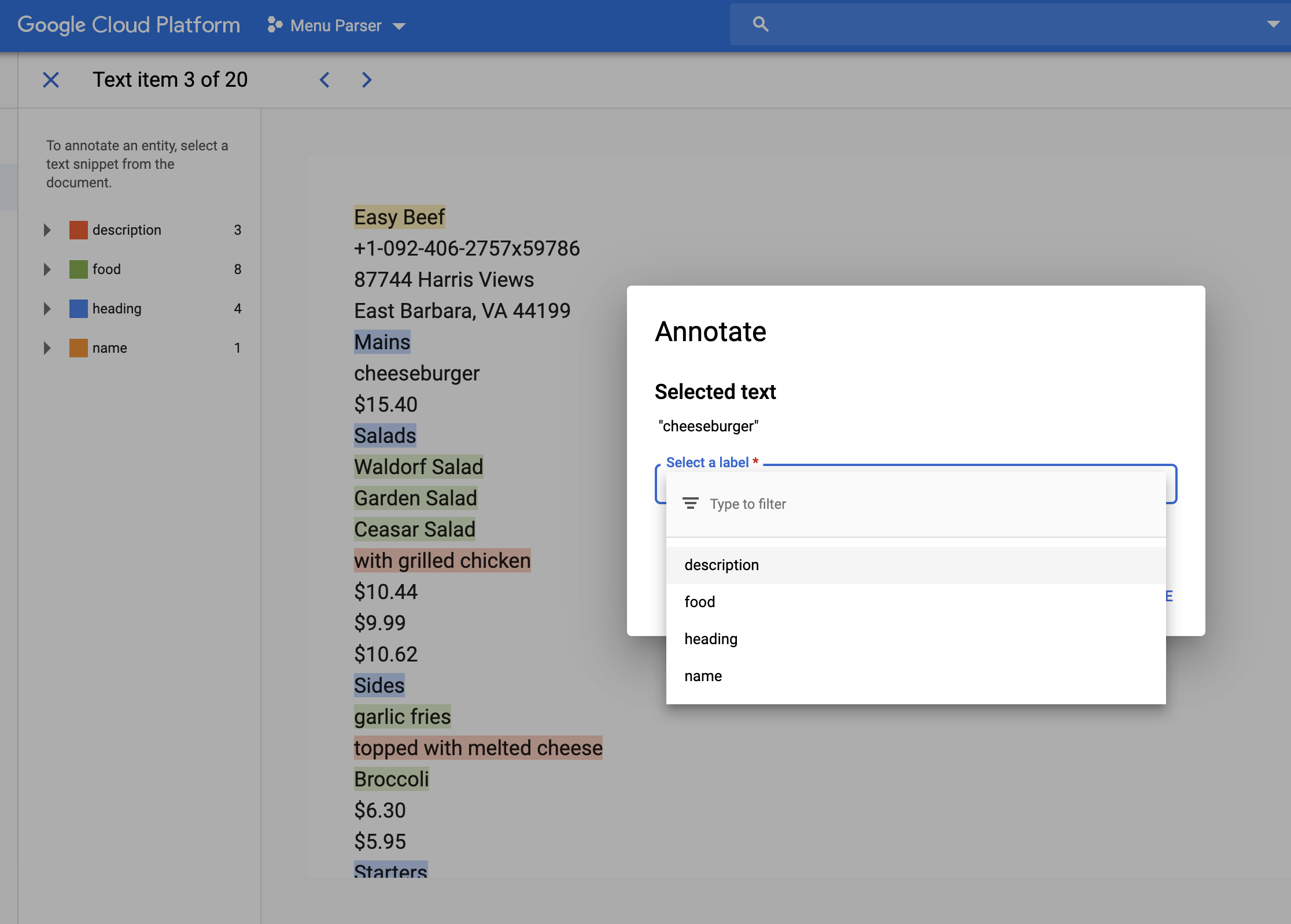
In retrospect, I probably should have used a data labeling service so I didn’t have to waste time labeling myself (or interns, maybe?).
I also scraped Wikipedia’s cuisine pages and generated some fake menus to help augment my dataset.
Training a Model
With Google AutoML, the hardest part of building a model is building a labeled dataset. Actually training a model with that data is pretty straightforward — just hop into the “Train” tab and click “Start Training.” It takes about 4 hours to build a custom model.
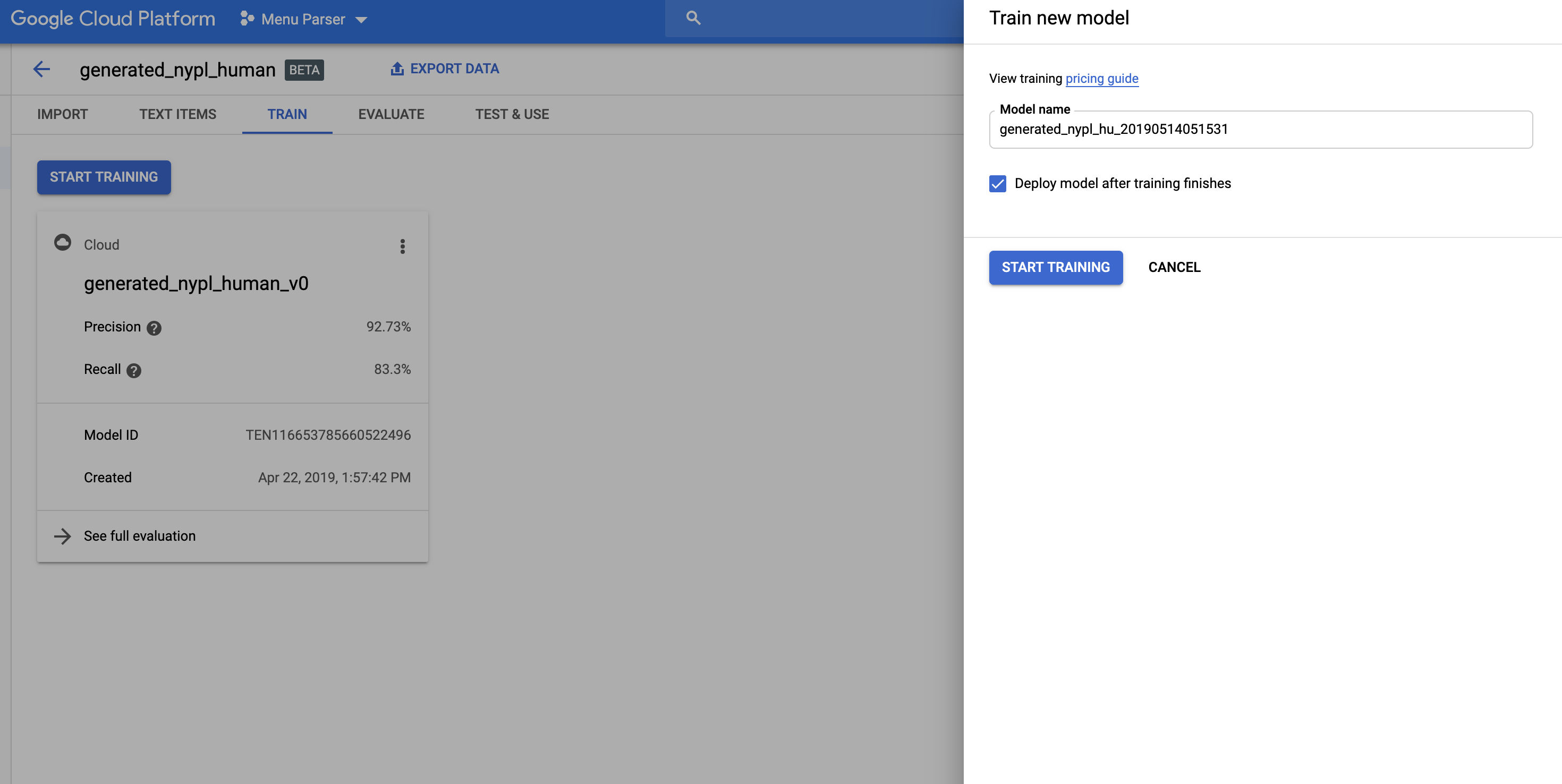
Making Predictions
When our entity extraction model is done training, we can test it out in the AutoML UI:
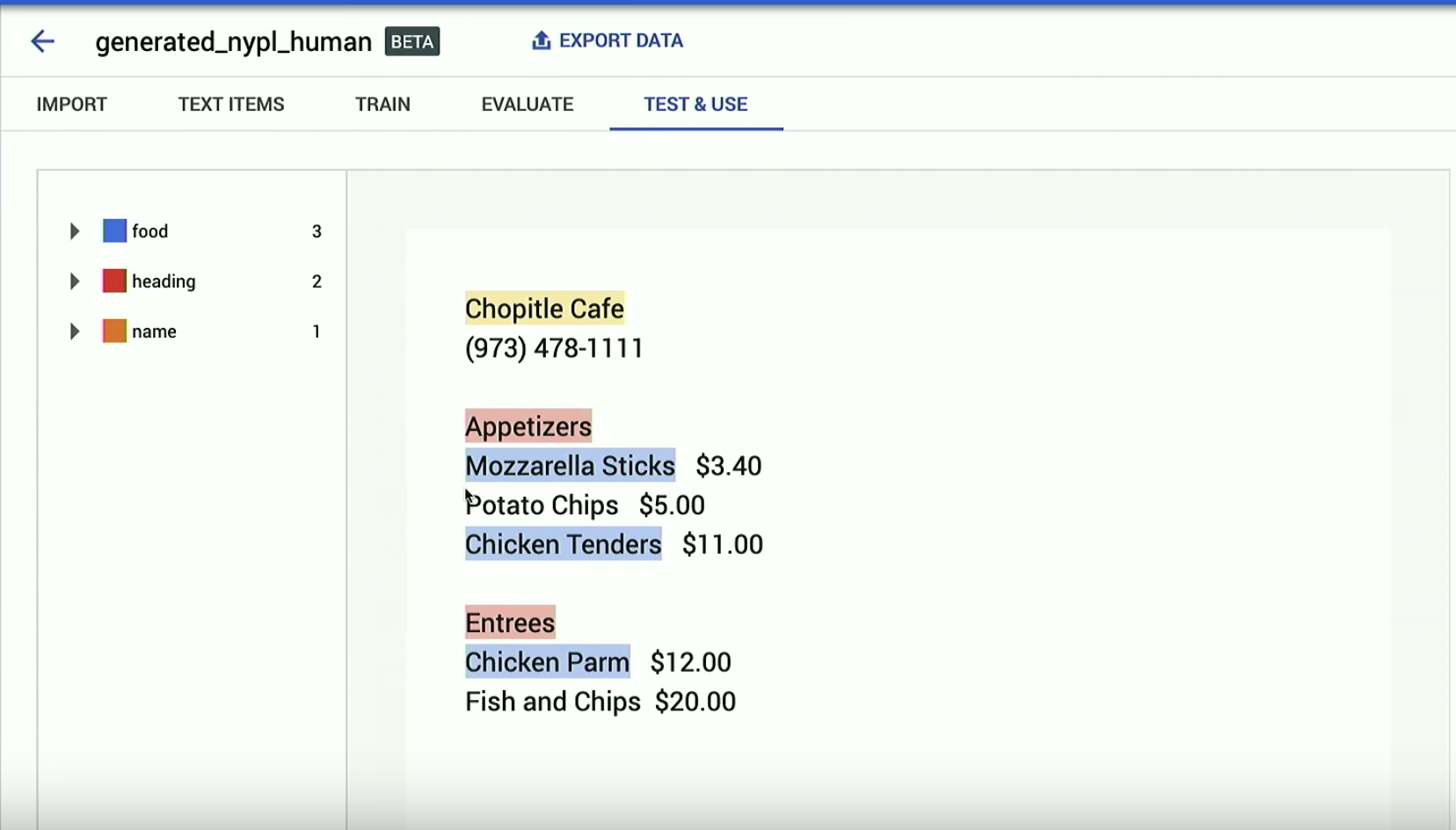
As you can see, it doesn’t work perfectly.
But what do you want?! That’s machine learning. It’s not perfect.
That said, not bad considering I had a pretty small dataset (less than 150 menus). I also didn’t take into account things like the size of the text or its location on the page (headers are usually bigger than dish names, and dishes are bigger than their descriptions).
But still, if I were a restaurant and I could use this tool to import my menu instead of manually typing out every single food by hand, I’d save lots of time (though I might have to do a bit of editing). Plus, the more hypothetical restaurants use my app, the more hypothetical data points I’ll get to improve my model.
Meanwhile, lunch at the Google Cafe calls. Ciao.
P.S. If you train your own entity extraction model, tell me about it in the comments or @dalequark.
Happy Modeling!